
Abstract
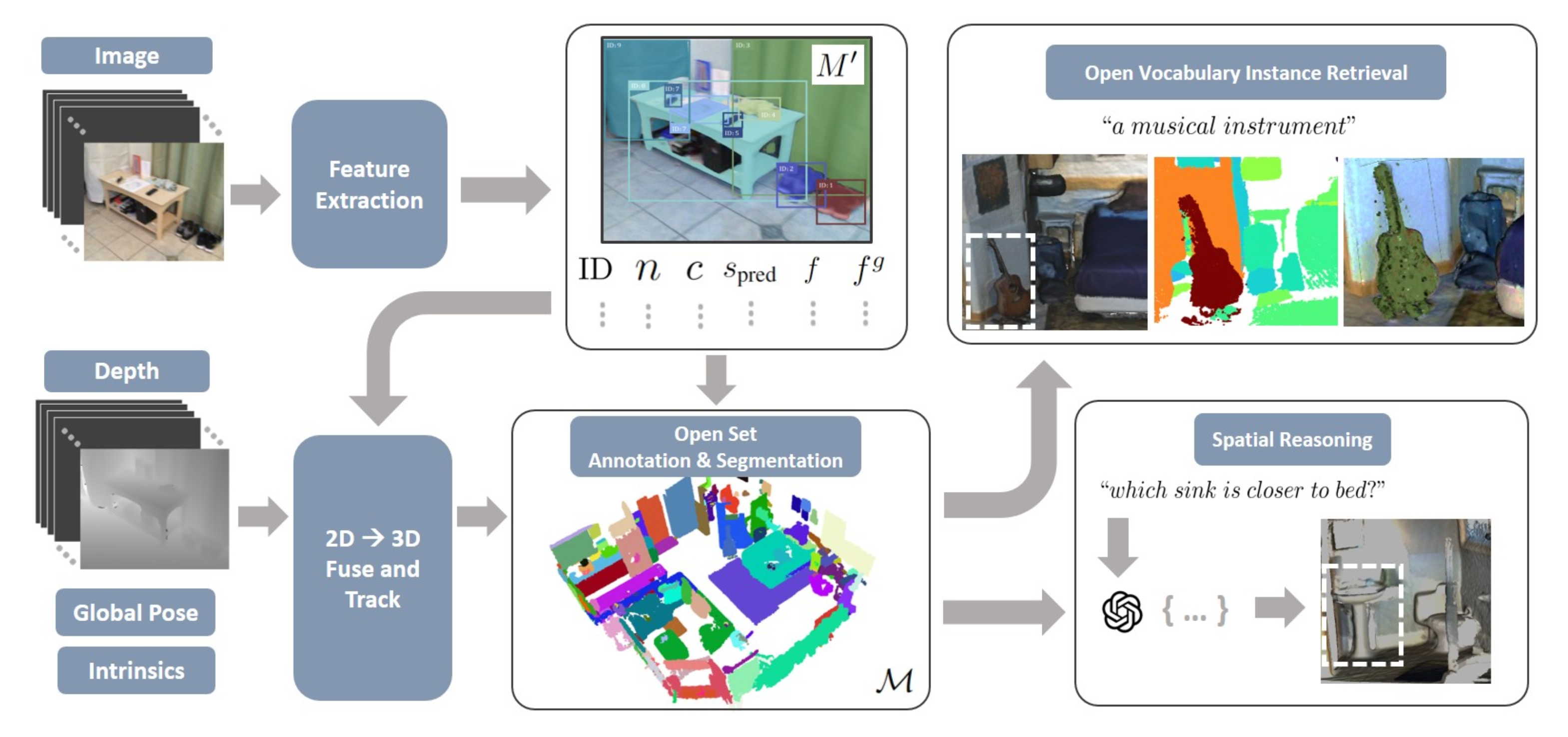
This study present a novel, scalable approach for constructing open set, instance-level 3D scene representations, advancing open world understanding of 3D environments. Existing methods require pre-constructed 3D scenes and face scalability issues due to per-point feature representation, additionally struggle with contextual queries. Our method overcomes these limitations by incrementally building instancelevel 3D scene representations using 2D foundation models, and efficiently aggregating instance-level details such as masks, feature vectors, names, and captions. We introduce fusion schemes for feature vectors to enhance their contextual knowledge and performance on complex queries. Additionally, we explore large language models for robust automatic annotation and spatial reasoning tasks. We evaluate our proposed approach on multiple scenes from ScanNet and Replica datasets demonstrating zero-shot generalization capabilities, exceeding current state-of-the-art methods in open world 3D scene understanding.
Video
Comparision





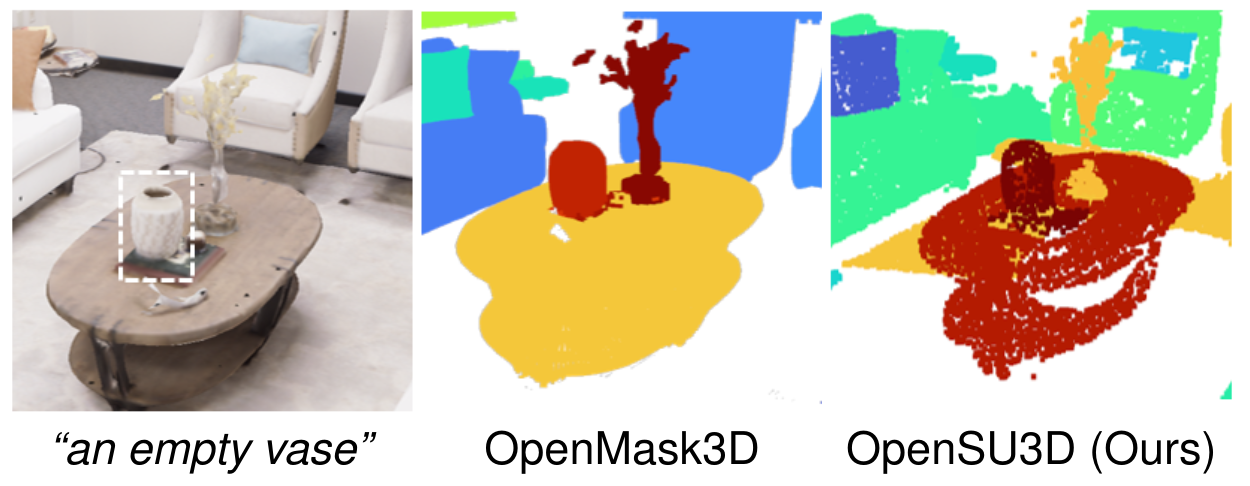
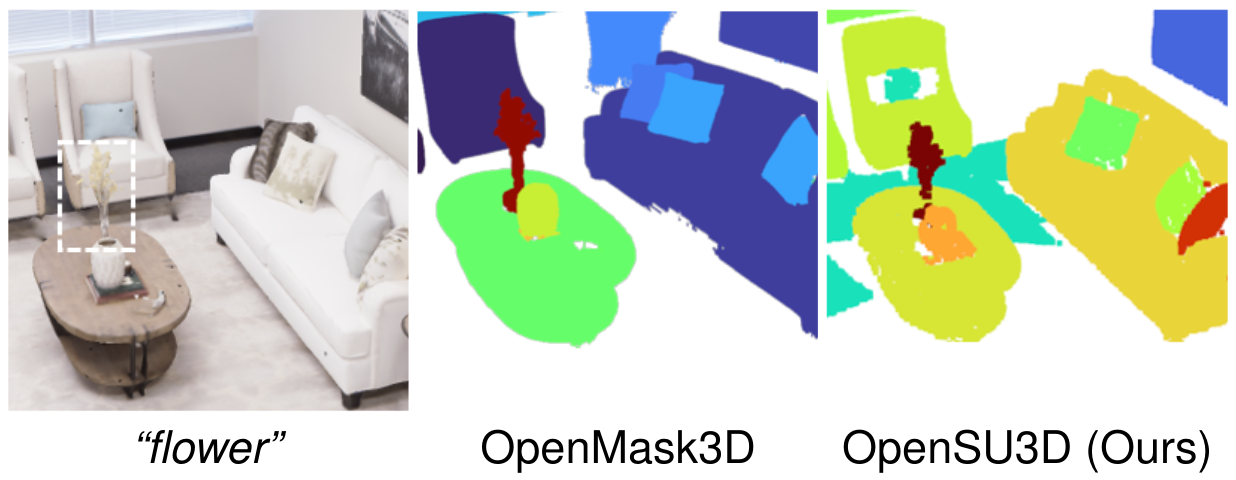

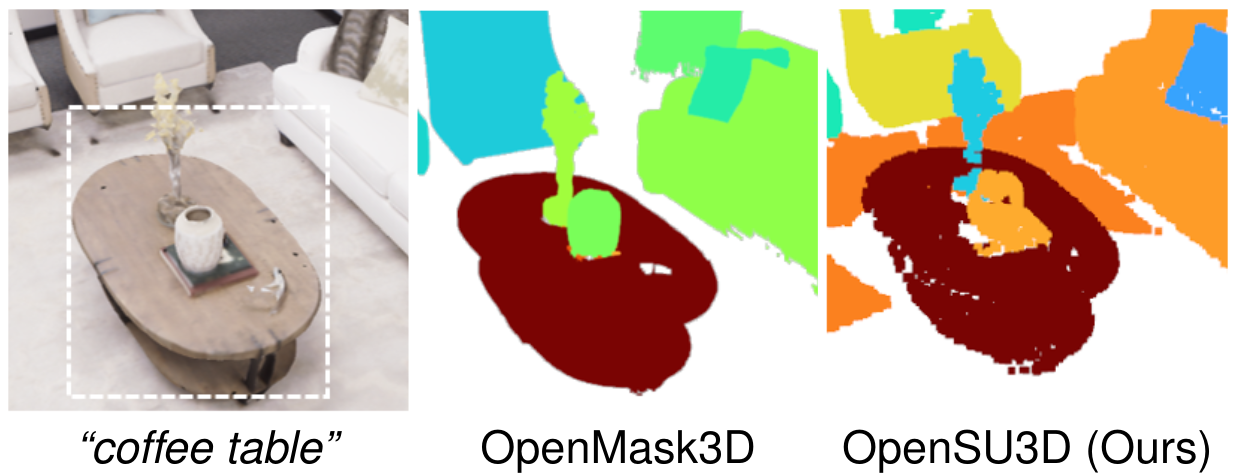

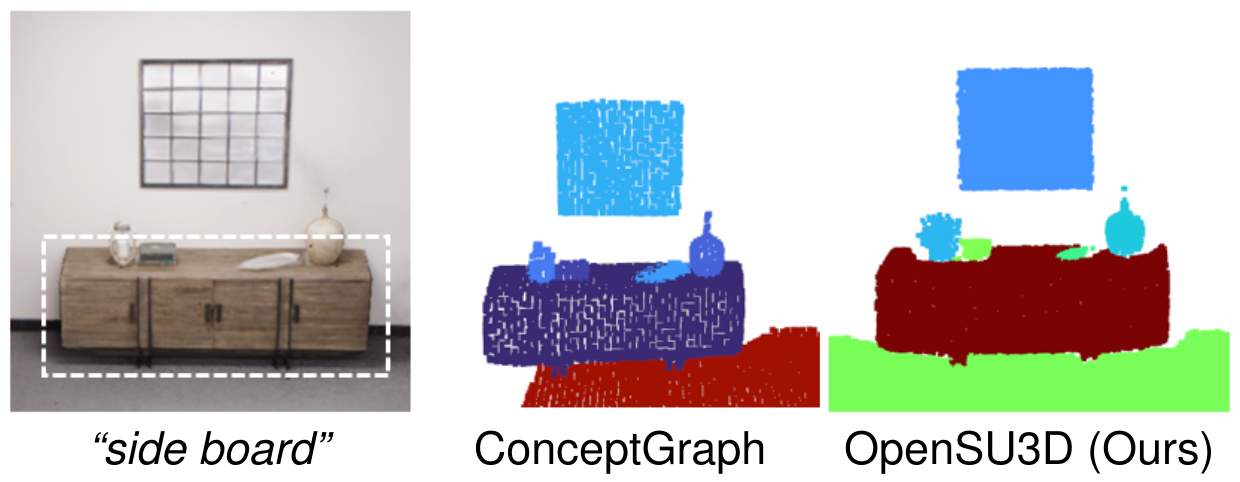
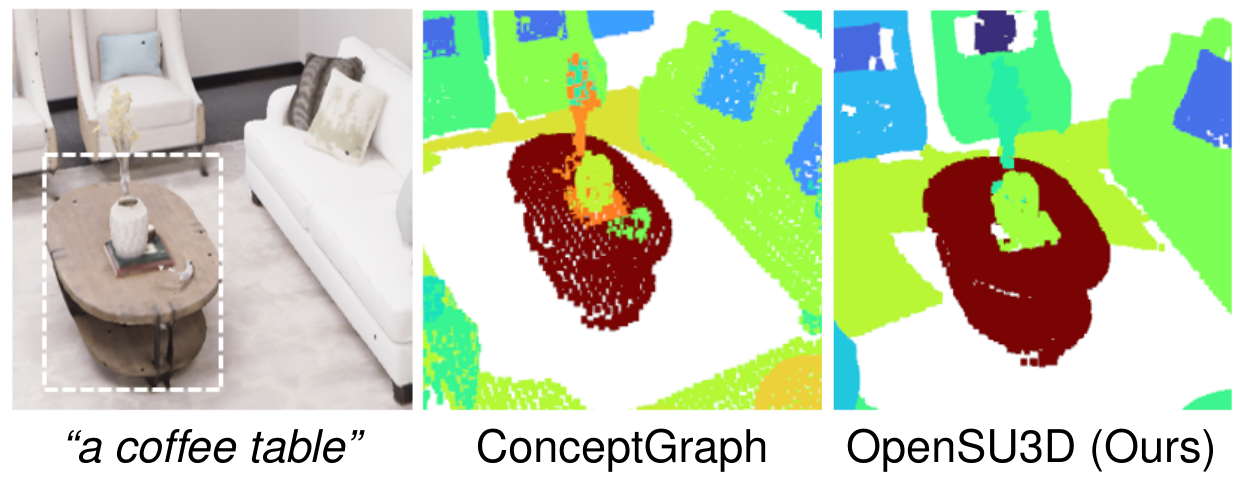

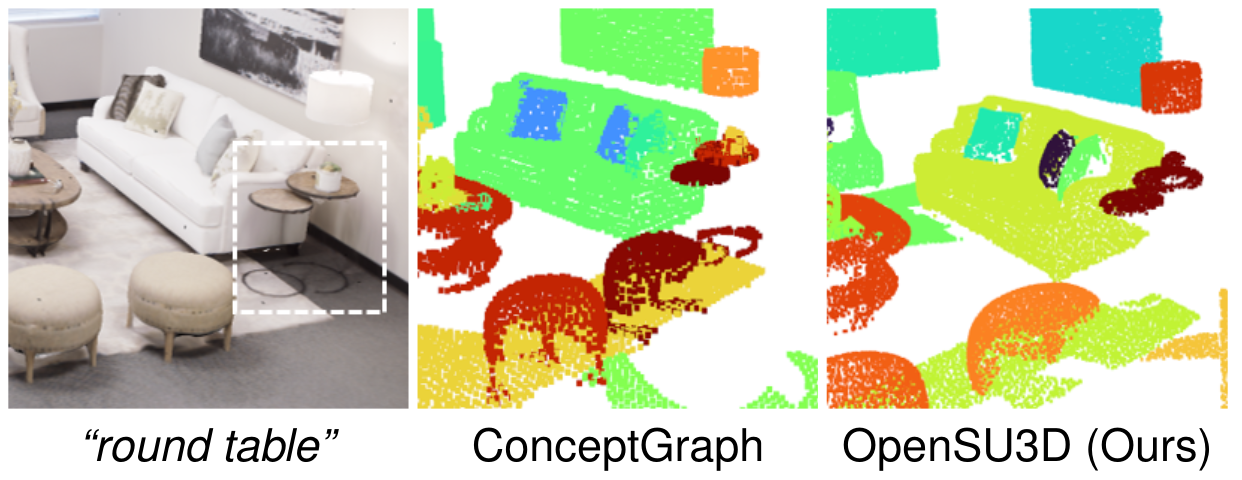

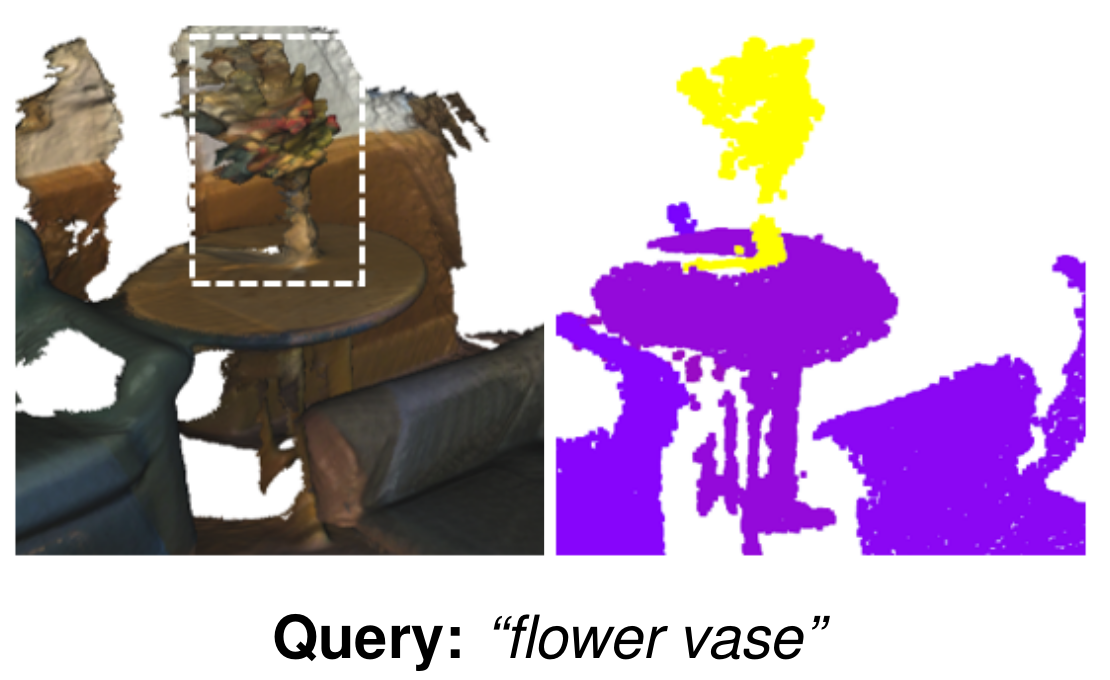
Open Vocabulary Queries
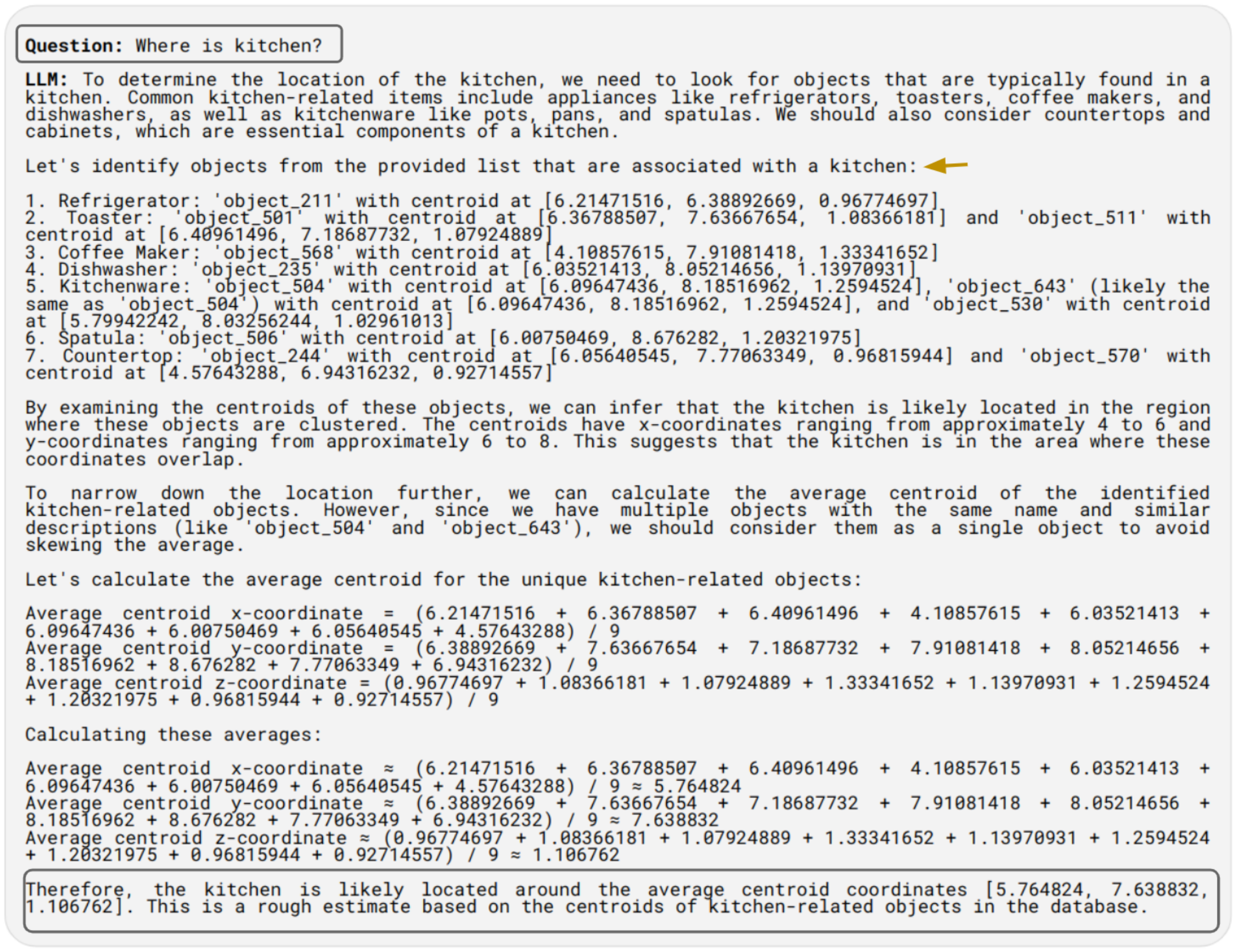
Instance Queries










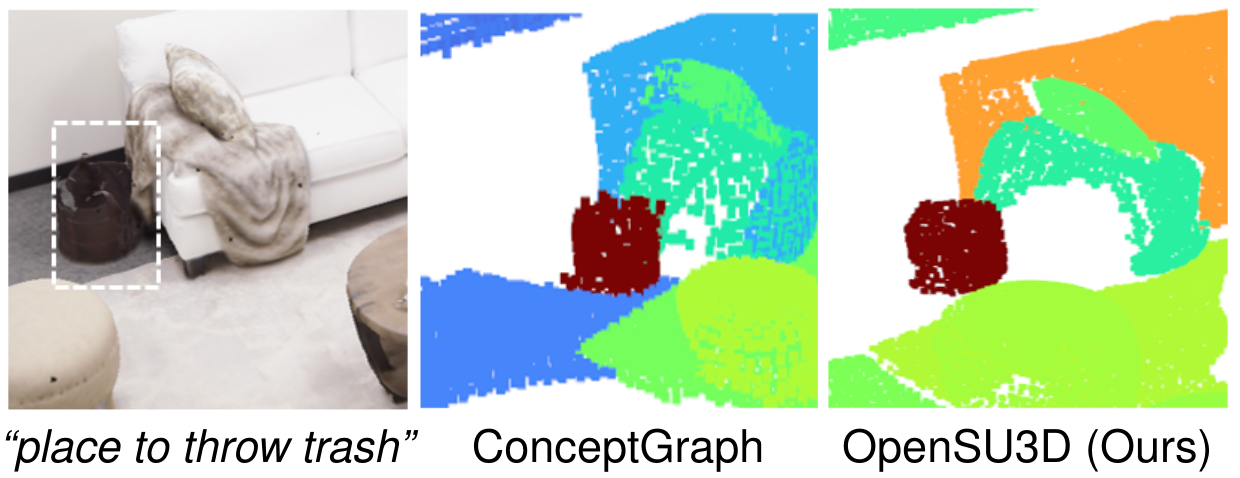
Affordance Queries












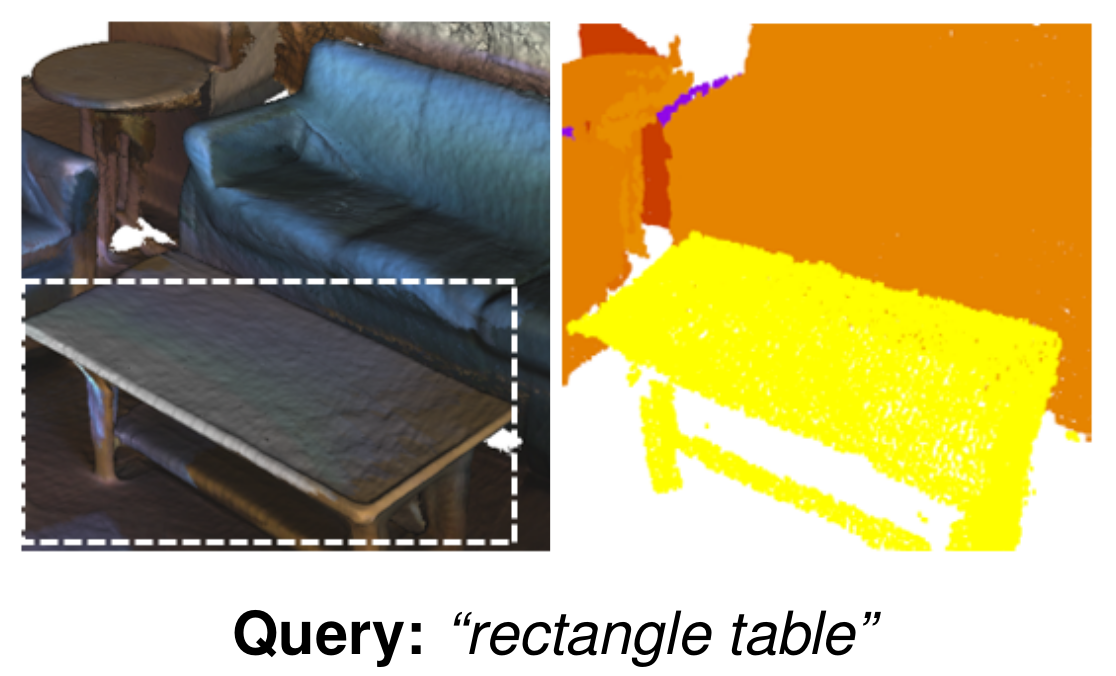
Property Queries






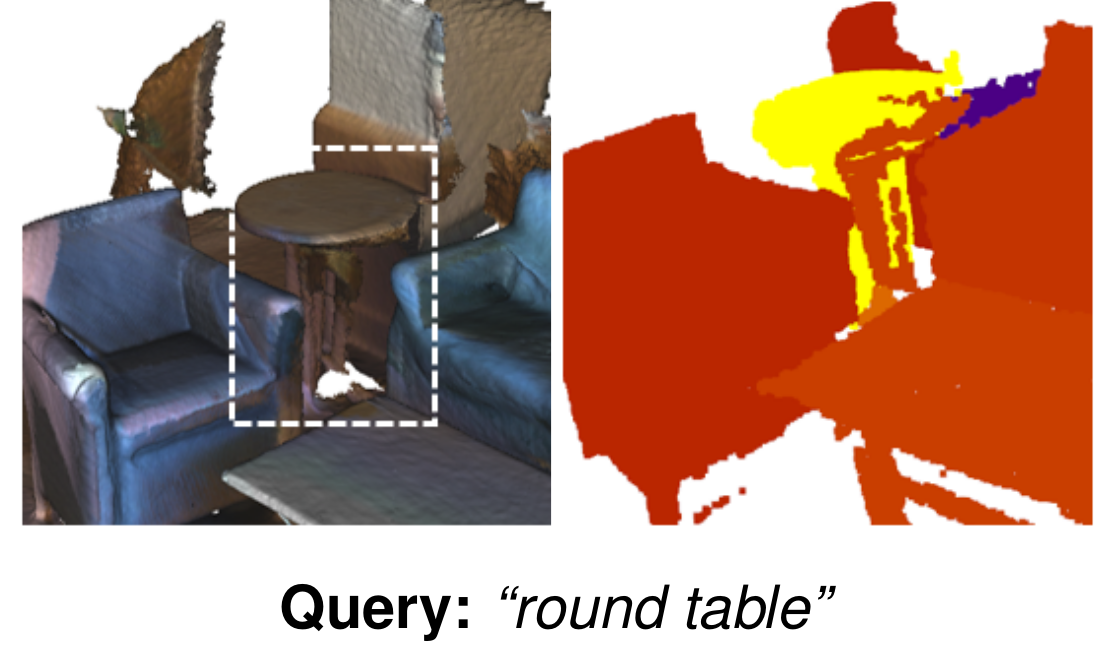




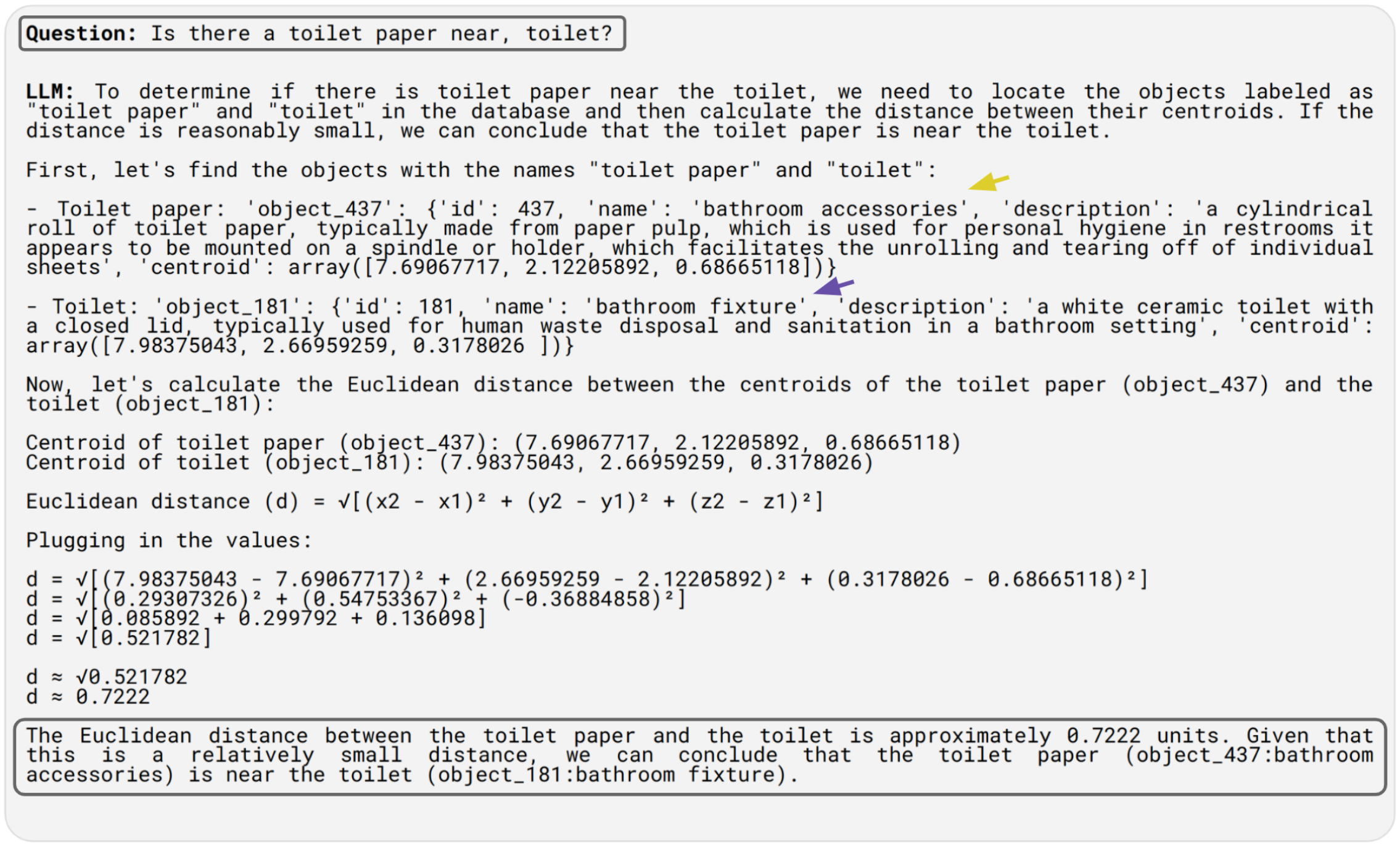
Relative Queries







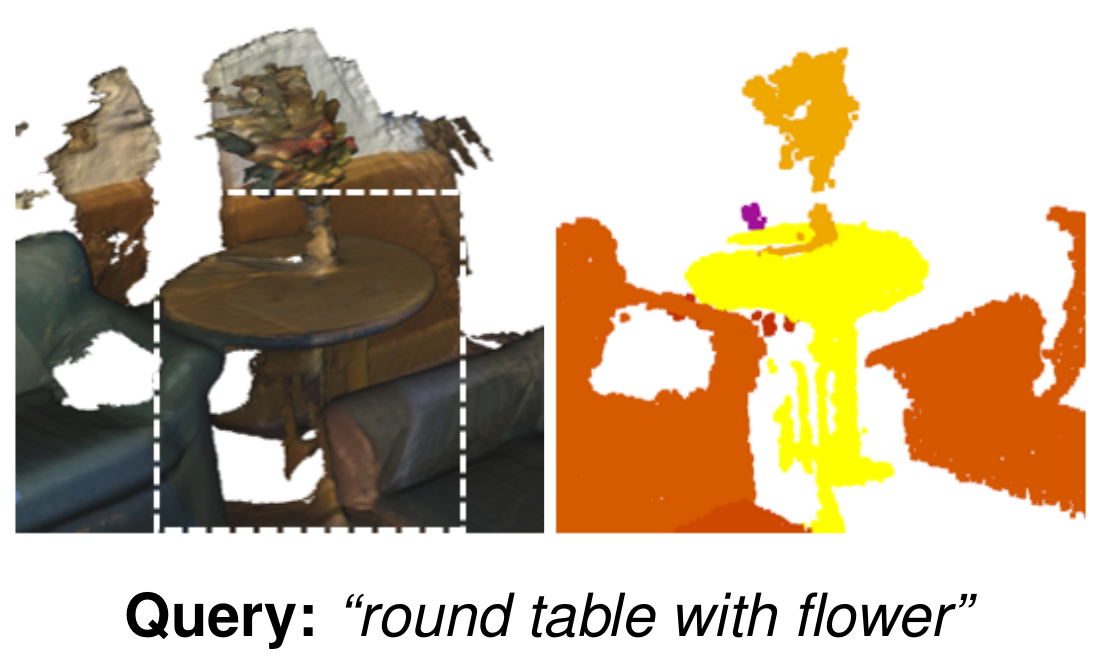



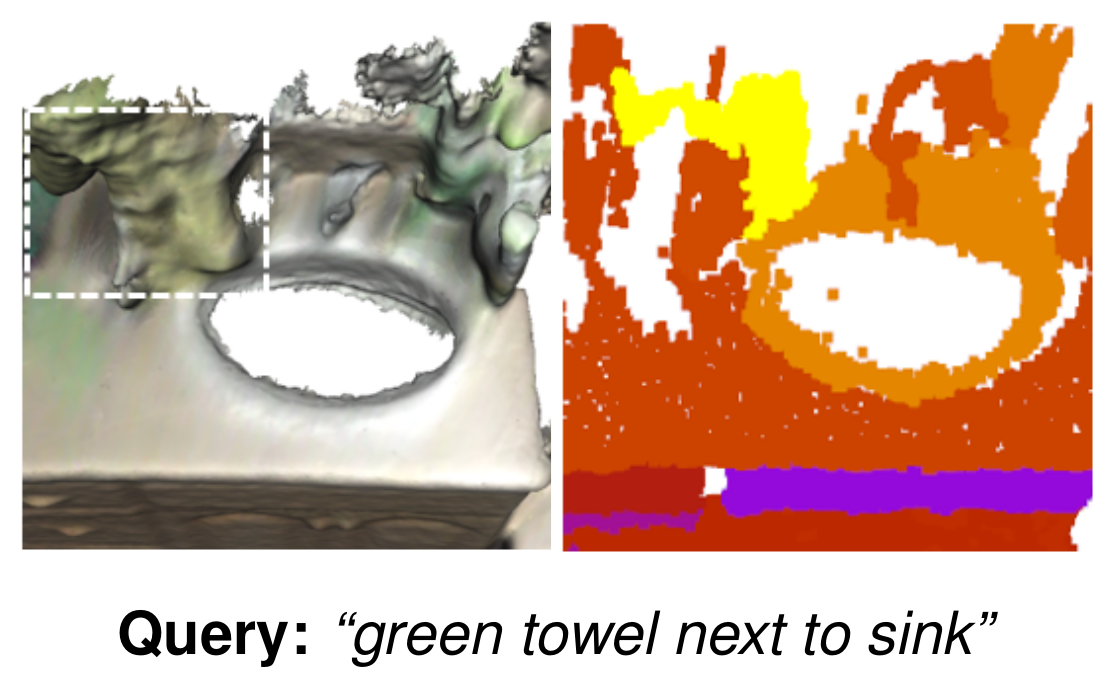
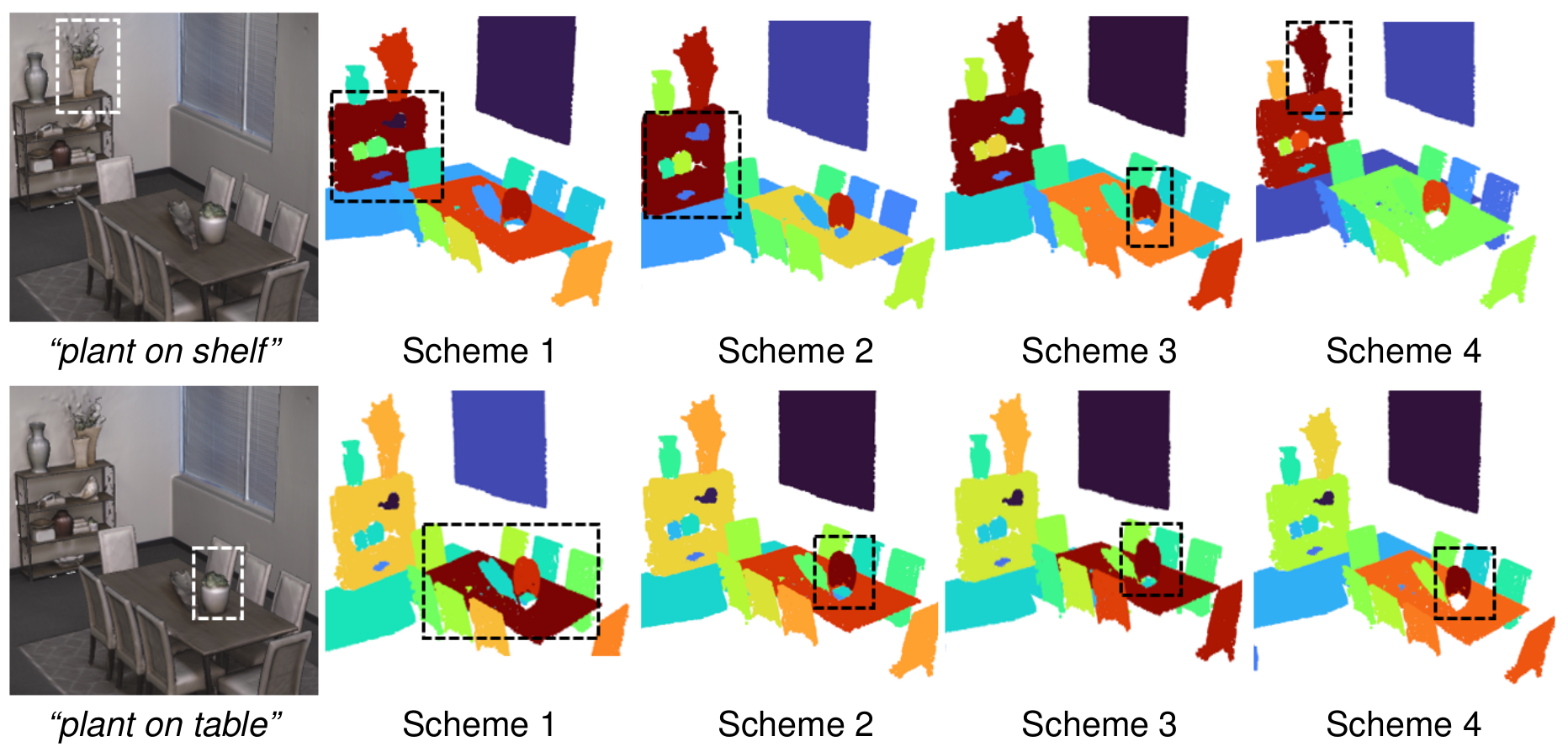
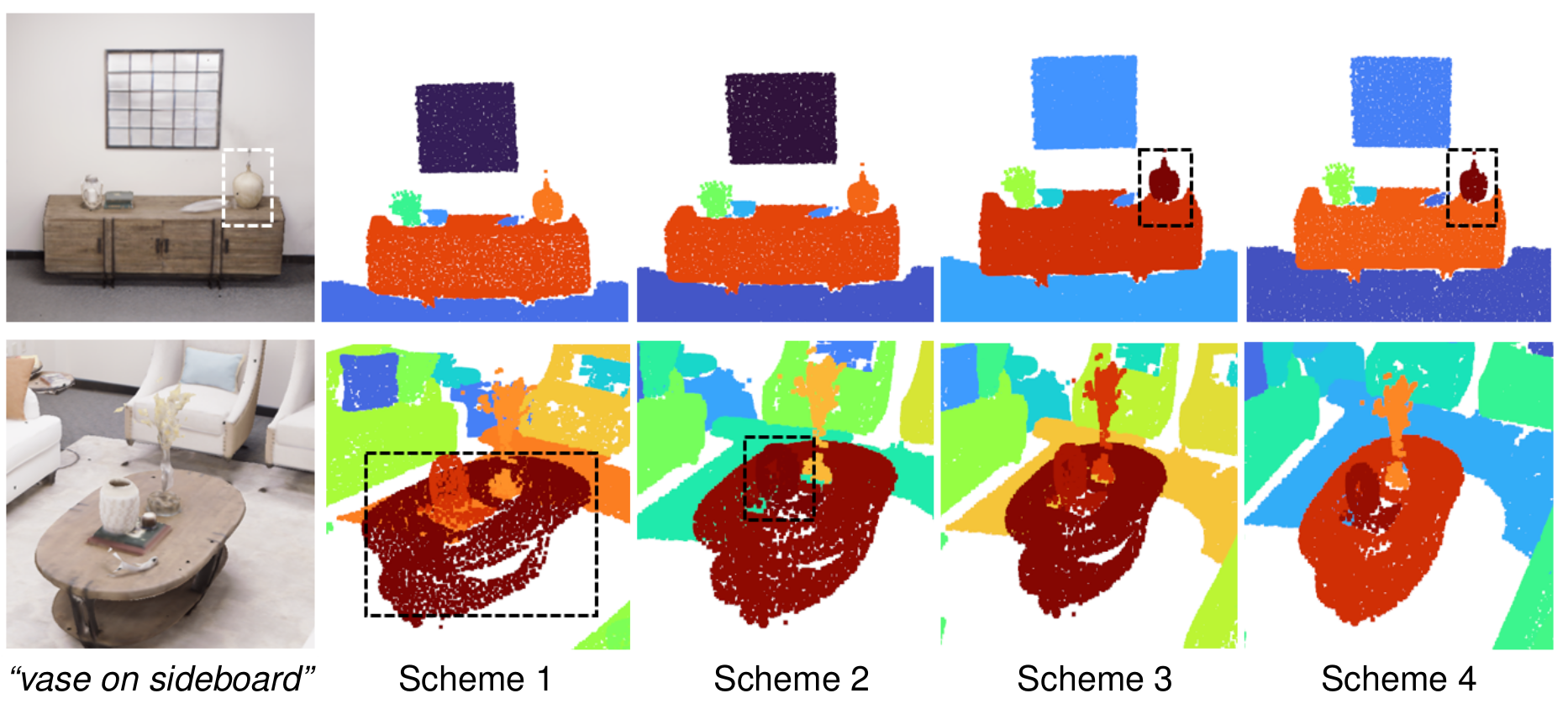
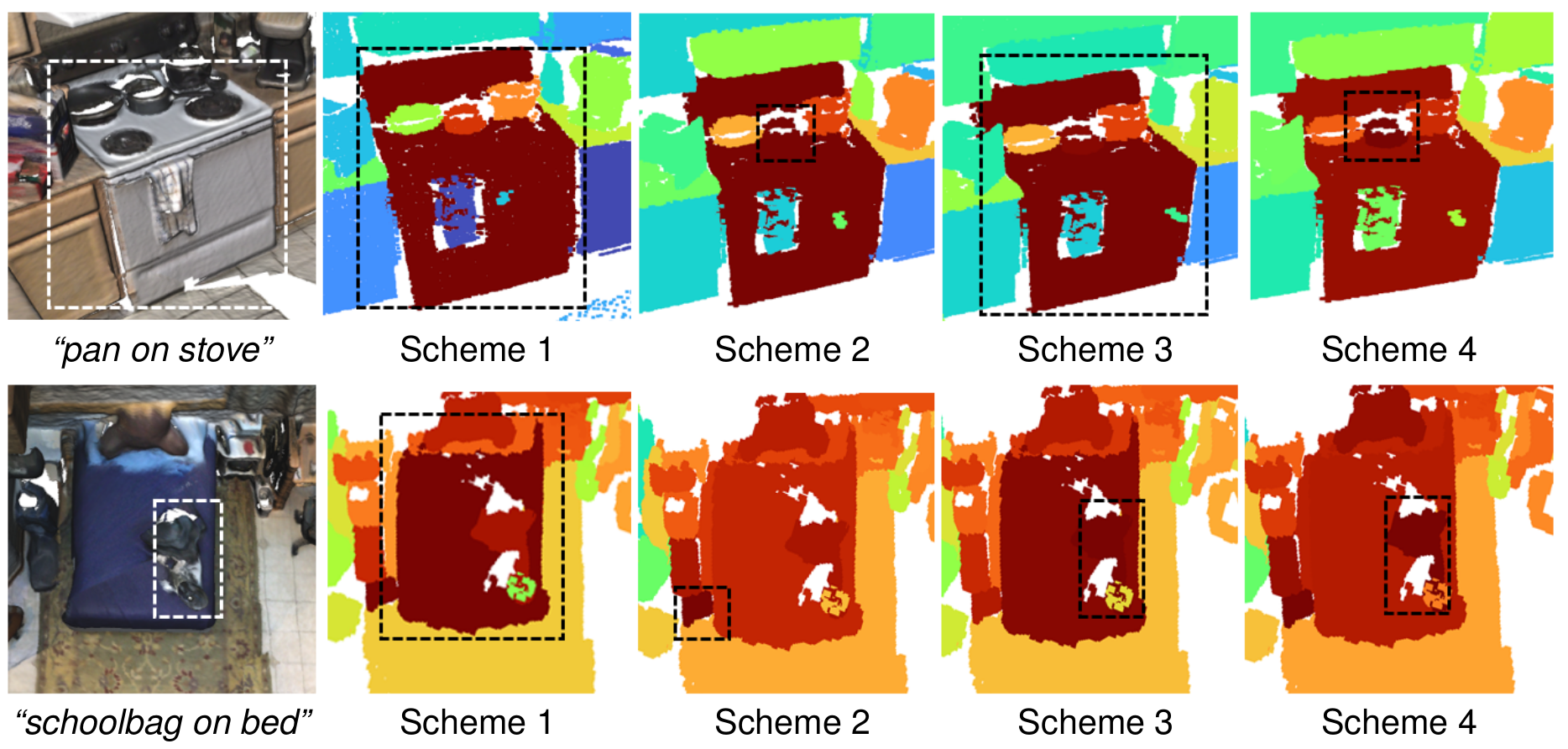
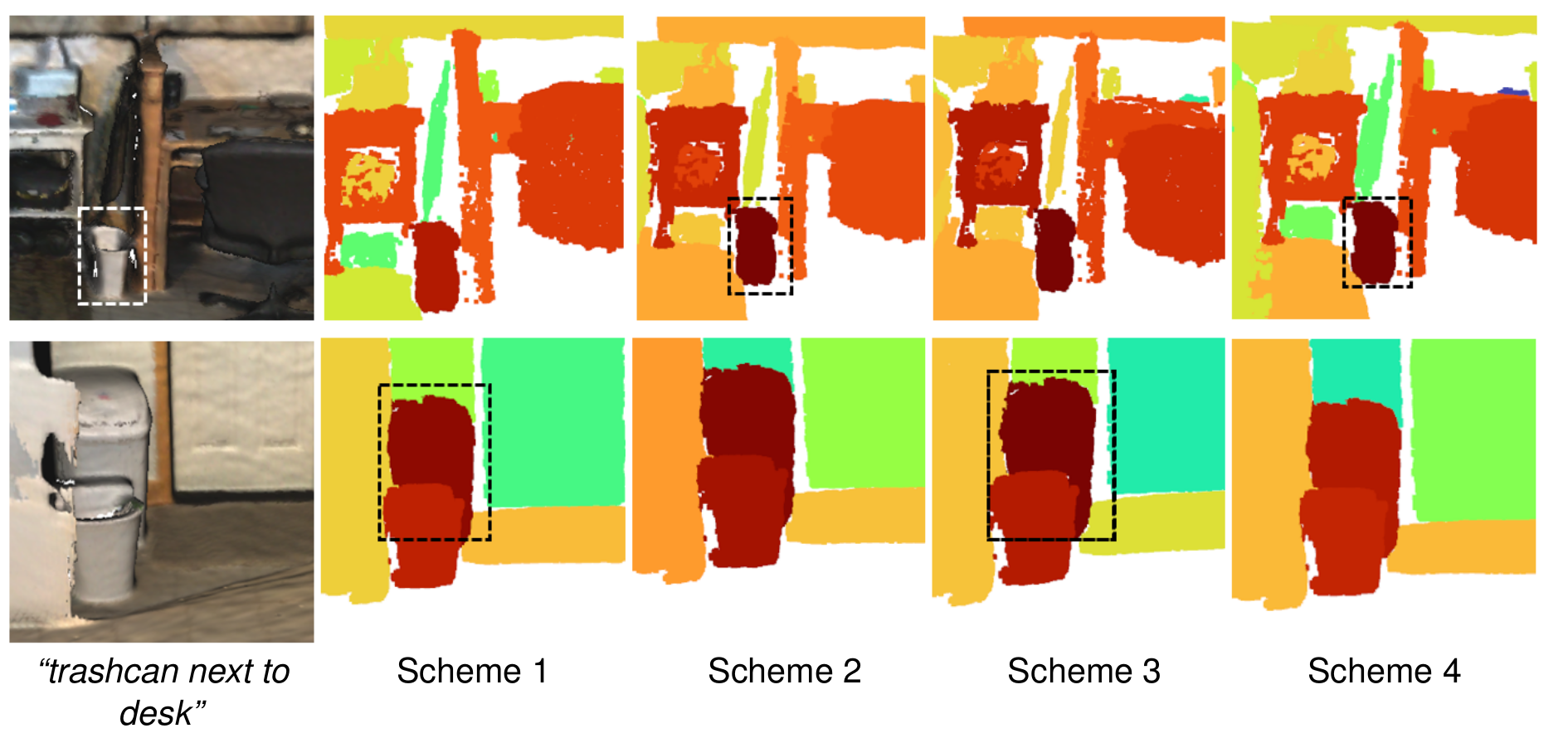
Feature Fusion Schemes
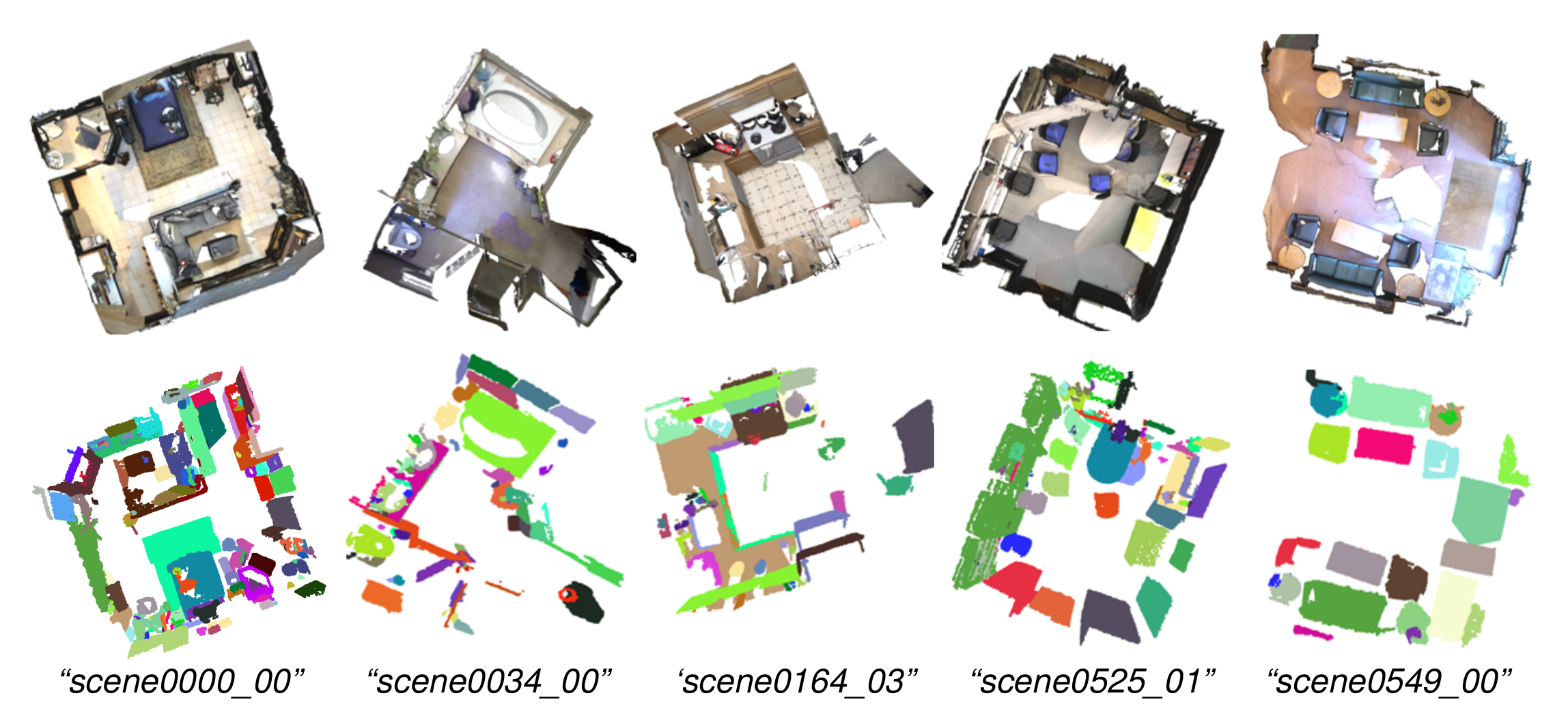
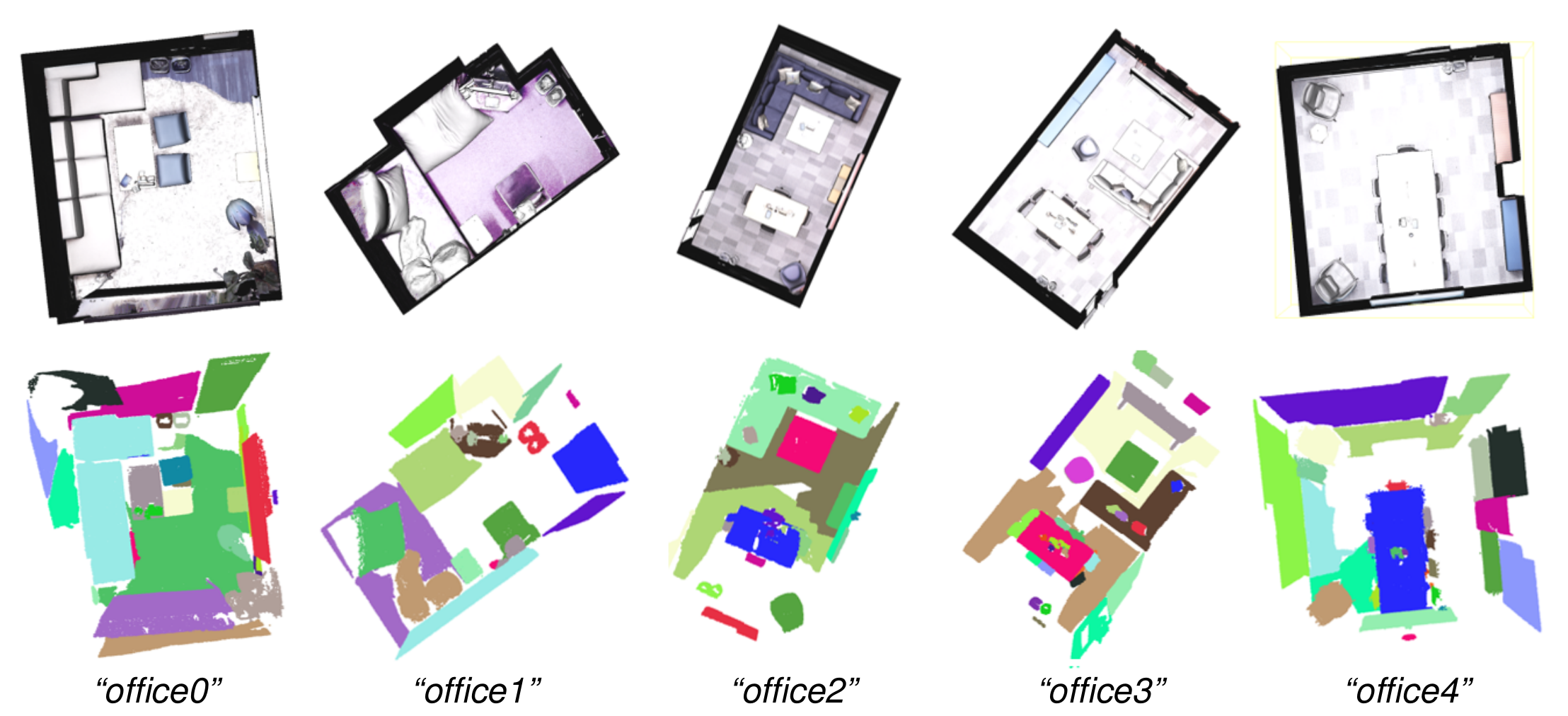
Instance Segmentation
Automatic Annotation



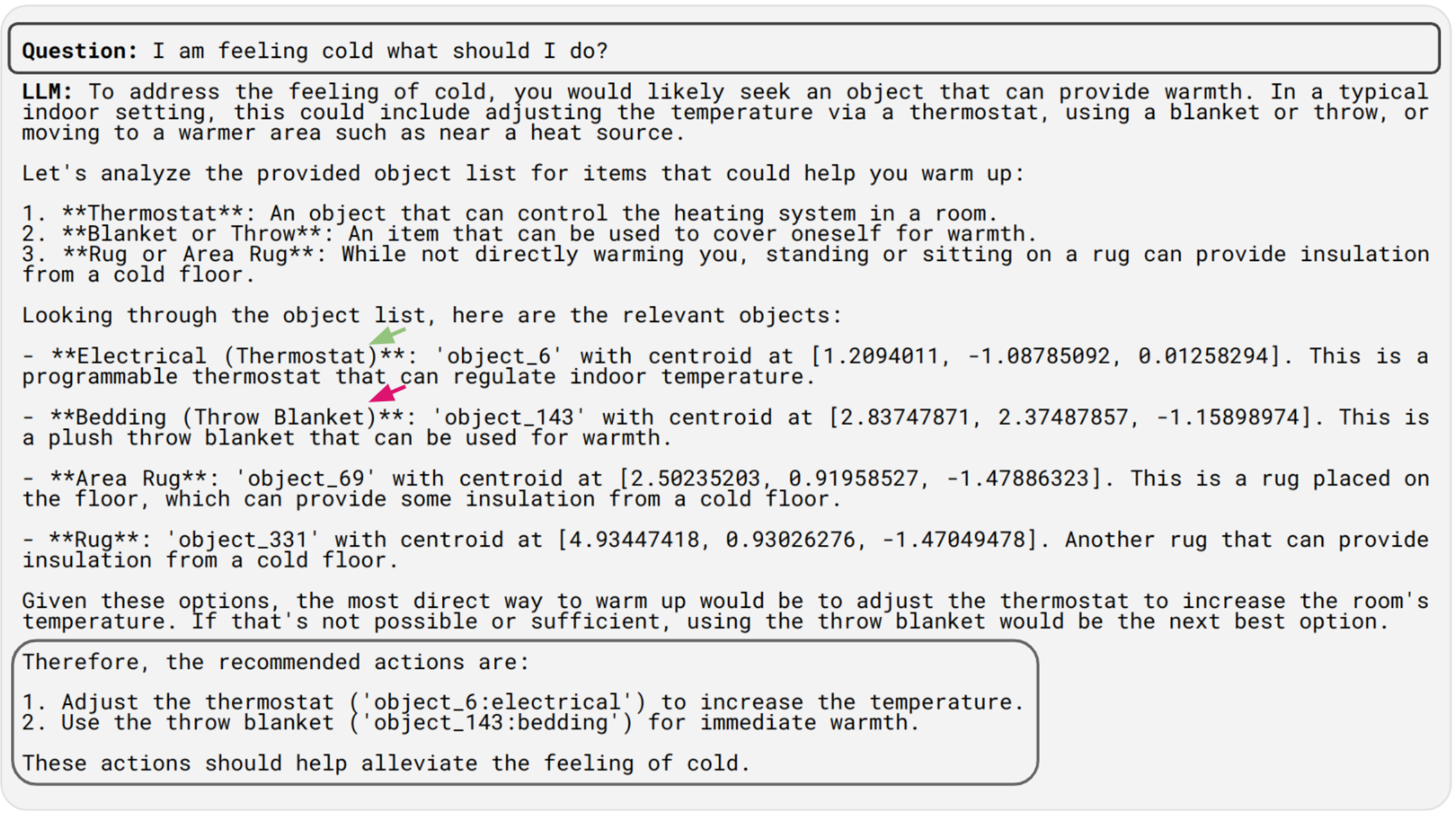
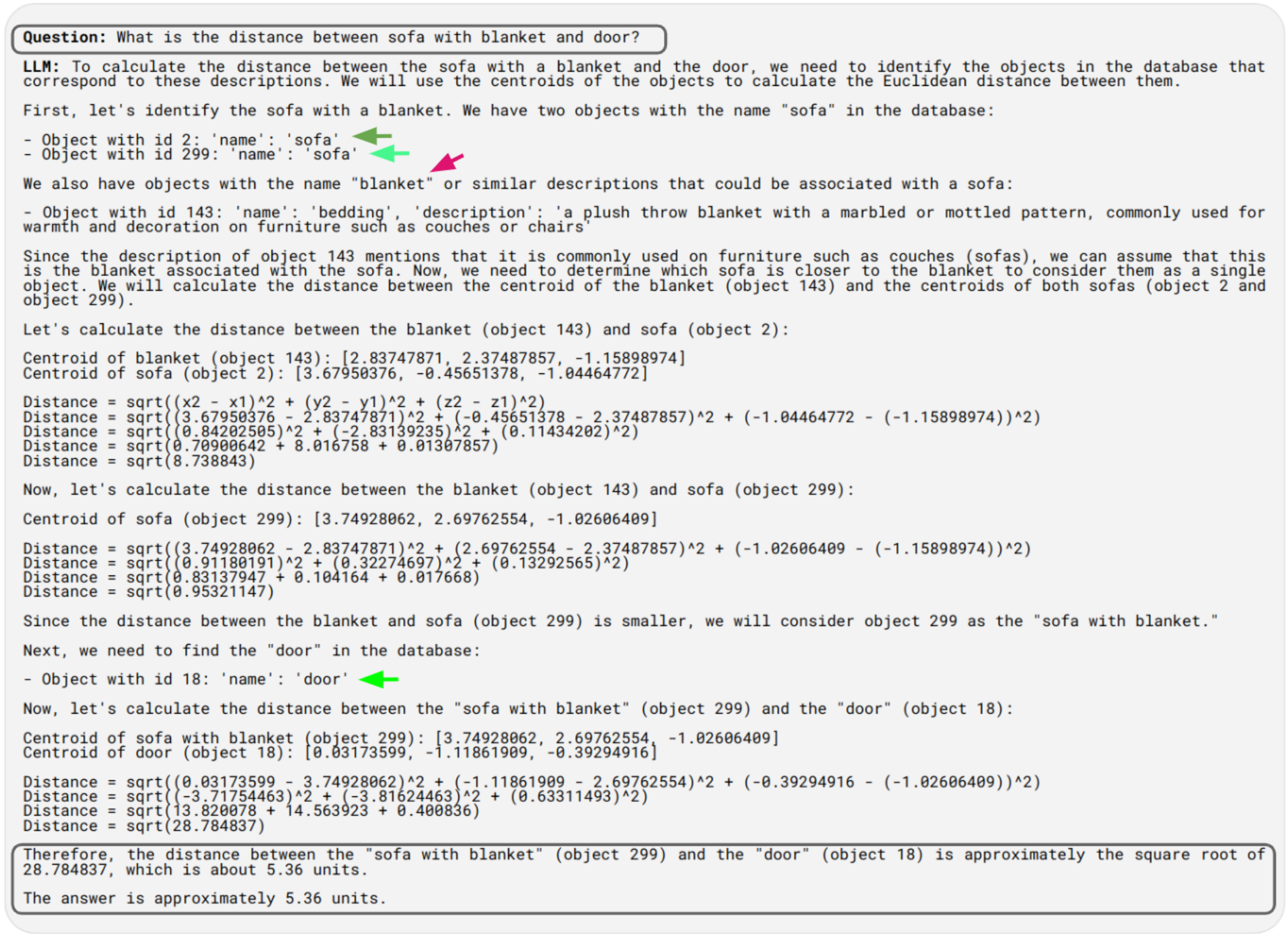
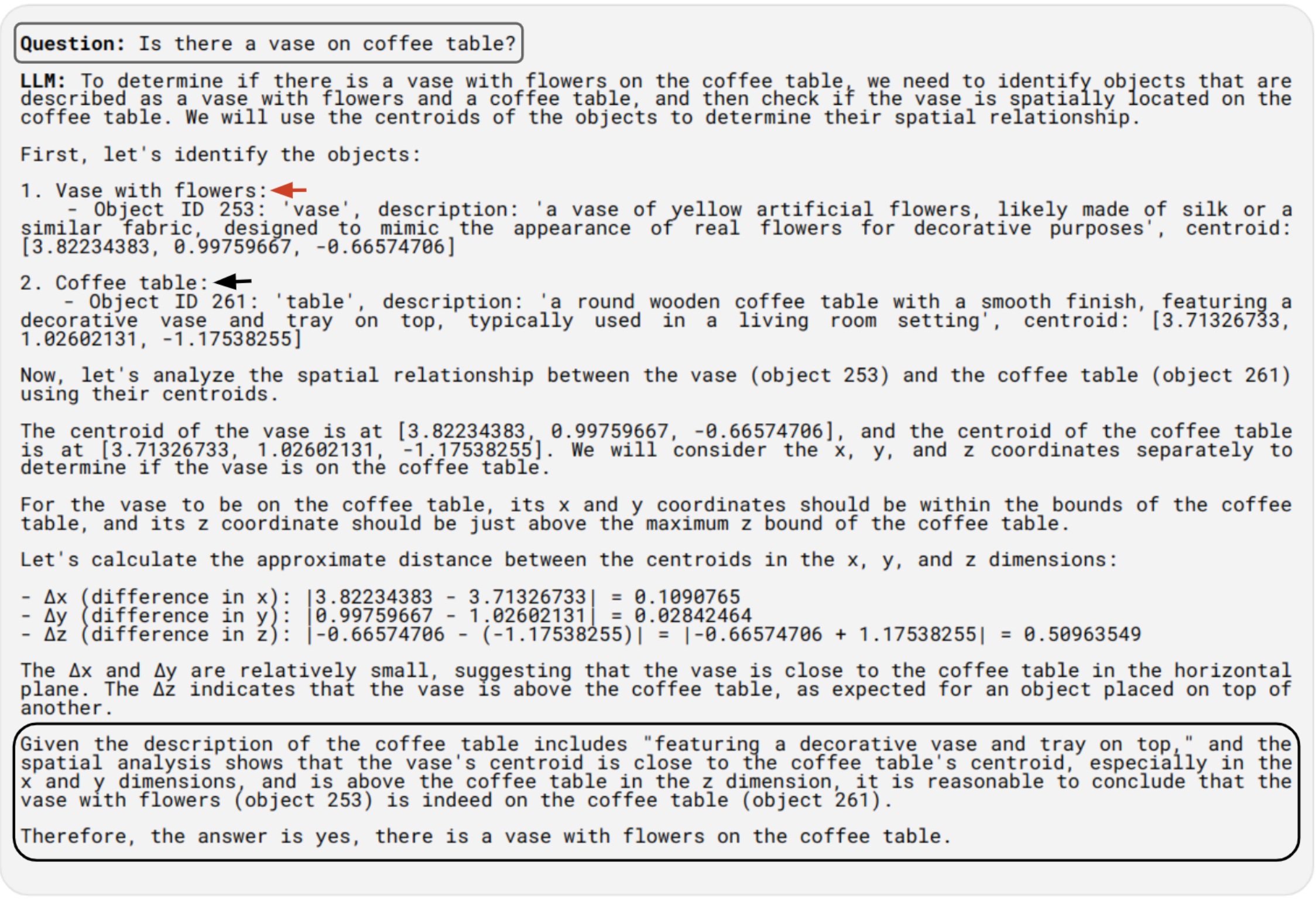
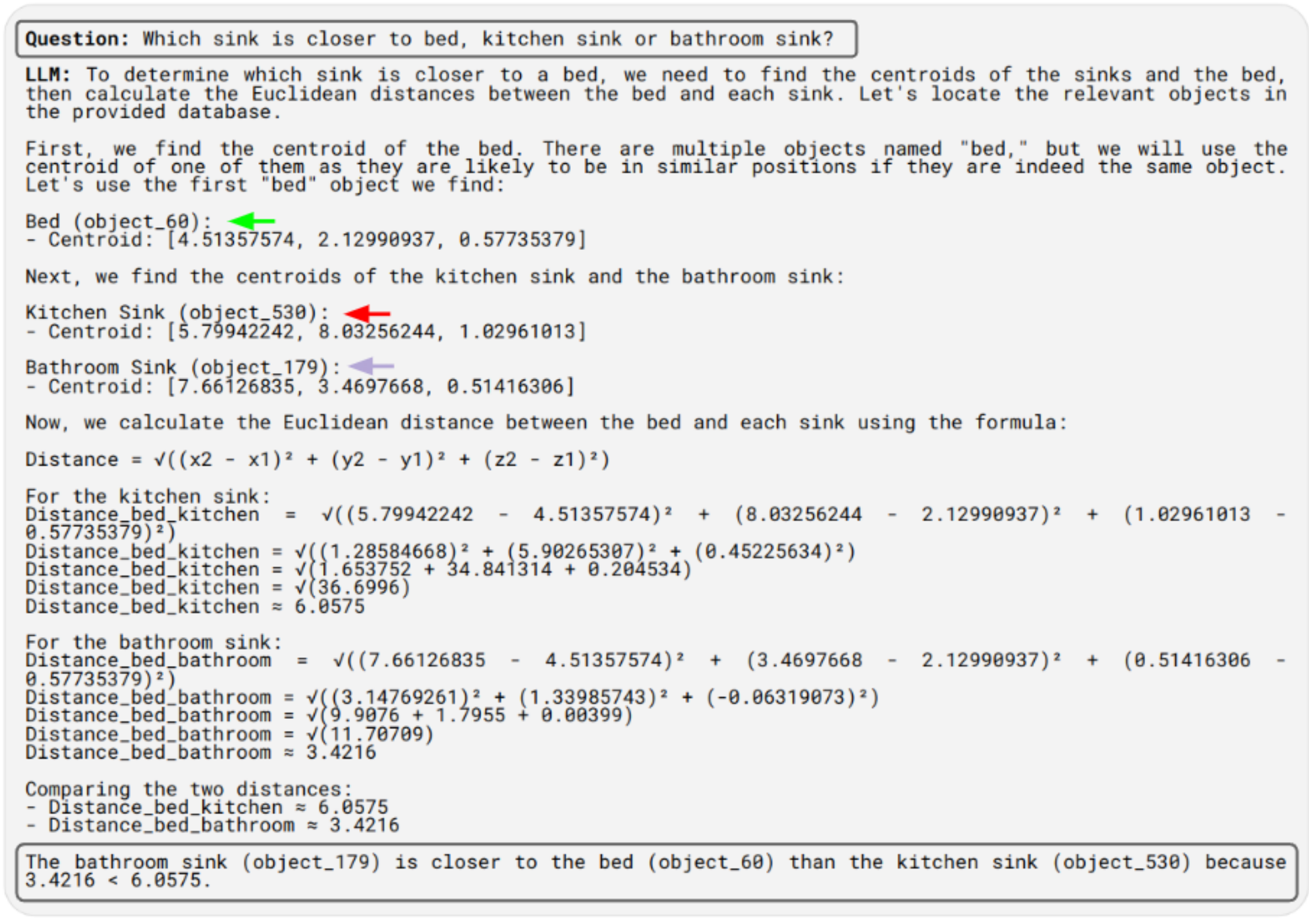
Spatial Reasoning


Related Links
Our work emerged alongside a lot of other great research on 3D scene understanding. The fast pace of AI research makes it really hard to stay on top of all the new studies happening in these fields. Several concurrent methods OpenIns3D, Segment3D, SayPlan, LangSplat etc. explore open world 3D scene understanding.
Among them, OVSG and ConceptGraph align closely with our incremental, scalable instance-based representation approach.
Our approch rely only on geometric principles for merging 3D masks. While others build scene graphs for spatial reasoning, we leverage large language model's innate reasoning abilities through tailored prompts.
BibTeX
@INPROCEEDINGS{11127896,
author={Mohiuddin, Rafay and Prakhya, Sai Manoj and Collins, Fiona and Liu, Ziyuan and Borrmann, André},
booktitle={2025 IEEE International Conference on Robotics and Automation (ICRA)},
title={OpenSU3D: Open World 3D Scene Understanding Using Foundation Models},
year={2025},
pages={13560-13566},
doi={10.1109/ICRA55743.2025.11127896}}